
Nvidia Drive has prepared the PredictionNet deep neural network to understand the driving environment around a car in top-down or bird’s-eye view and to predict the future trajectories of road users based on both live perception and map data.
PredictionNet examines past movements of all road agents, such as cars, buses, trucks, bicycles, and pedestrians, to estimate their future movements. The DNN looks into the past to take in previous road user positions and also takes in positions of fixed objects and landmarks on the scene, such as traffic lights, traffic signs, and lane line markings provided by the map.
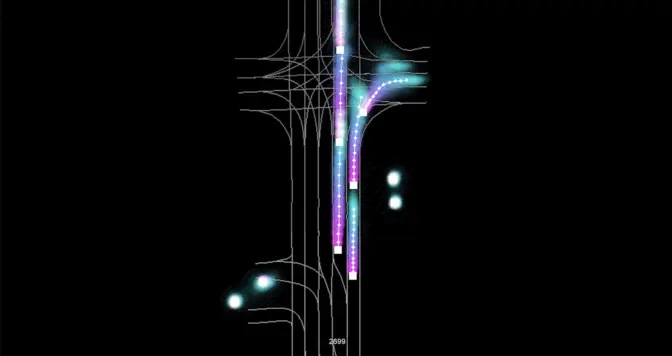
Based on these inputs, which are rasterized in top-down view, the DNN predicts road user trajectories into the future, as shown in figure 1.
A Top-Down Convolutional RNN-Based Approach
PredictionNet, Nvidia adopts an RNN-based architecture that uses two-dimensional convolutions. This structure is highly scalable for arbitrary input sizes, including the number of road users and prediction horizons.
As is typically the case with any RNN, different time steps are fed into the DNN sequentially. Each time step is represented by a top-down view image that shows the vehicle surroundings at that time, including both dynamic obstacles observed via live perception, and fixed landmarks provided by a map.
This top-down view image is processed by a set of 2D convolutions before being passed to the RNN. In the current implementation, PredictionNet is able to confidently predict one to five seconds into the future, depending on the complexity of the scene (for example, highway versus urban).
The PredictionNet model also lends itself to a highly efficient runtime implementation in the TensorRT deep learning inference SDK, with 10 ms end-to-end inference times achieved on an NVIDIA TITAN RTX GPU.
Scalable Results
Results thus far have shown PredictionNet to be highly promising for several complex traffic scenarios. For example, the DNN can predict which cars will proceed straight through an intersection versus which will turn. It’s also able to correctly predict the car’s behavior in highway merging scenarios.
PredictionNet is able to learn velocities and accelerations of vehicles on the scene. This enables it to correctly predict speeds of both fast-moving and fully stopped vehicles, as well as to predict stop-and-go traffic patterns.
PredictionNet is trained on lidar data to achieve higher prediction accuracy. However, the inference-time perception input to the DNN can be based on any sensor input combination (that is, camera, radar, or lidar data) without retraining. This also means that the DNN’s prediction capabilities can be leveraged for various sensor configurations and levels of autonomy, from level 2+ systems all the way to level 4/level 5.
PredictionNet’s ability to anticipate behavior in real-time can be used to create an interactive training environment for reinforcement learning-based planning and control policies for features such as automatic cruise control, lane changes, or intersections handling.

