In recent years, we witnessed a gradual paradigm shift in personalized transport services from private vehicle ownership to mobility as a service application (MaaS). A MaaS provider operates a fleet of vehicles that ferry users from their pick-up locations to their drop-off locations at a time of their choosing. To achieve efficient vehicle utilization and overall economies of scale, a MaaS service typically employs a routing and scheduling algorithm to pool a number of users who are headed in similar directions at mutually compatible timings.
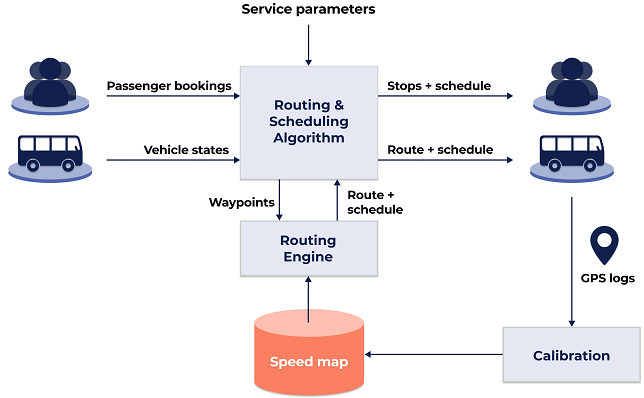
As illustrated in Figure 1, at the heart of a routing and scheduling algorithm is an optimization formulation, where millions of solution candidates, each comprising a permutation of routes and passengers, are evaluated and scored to derive the most optimal outcome while simultaneously satisfying a slew of constraints imposed by passenger bookings, vehicle states, as well as service parameters.
To support the evaluation of each solution candidate, the algorithm calls a routing engine to compute the shortest journey time for a route that passes through a set of waypoints. The routing engine takes into consideration the speed of the vehicle vis-à-vis the expected traffic condition of a road, the accessibility of the road given the vehicle’s size, turn restrictions and time penalties associated with navigational maneuvers. To ensure the accuracy of this evaluation, the routing engine taps a database of speed statistics, henceforth referred to as the speedmap.
This article describes an approach for designing, organizing, and calibrating the speedmaps deployed in our real services. Since 2016, we have successfully routed, scheduled and completed millions of rides with this speedmap approach, in numerous Asia Pacific cities such as Singapore, Tokyo, Sydney, Hanoi, Bangkok and Manila. The version of technology presented here has been appropriately modified or vaguely described in parts to safeguard our competitive interest, and to better serve the intended scope and objective of this educational piece.
A speedmap is a database comprising the statistics that summarily quantify the traffic speed distribution of a set of roads plied by the vehicles of a service. The statistics can be the mean, median, standard deviation and various percentiles of the traffic speed distributions.
In the simplest form, a speedmap consists of a singular, time-invariant average traffic speed for each road class. The same speed value is applicable to every way belonging to the same road class, day and night, weekday and weekend. It goes without saying that this is hardly realistic for modelling the traffic situations of most cities.
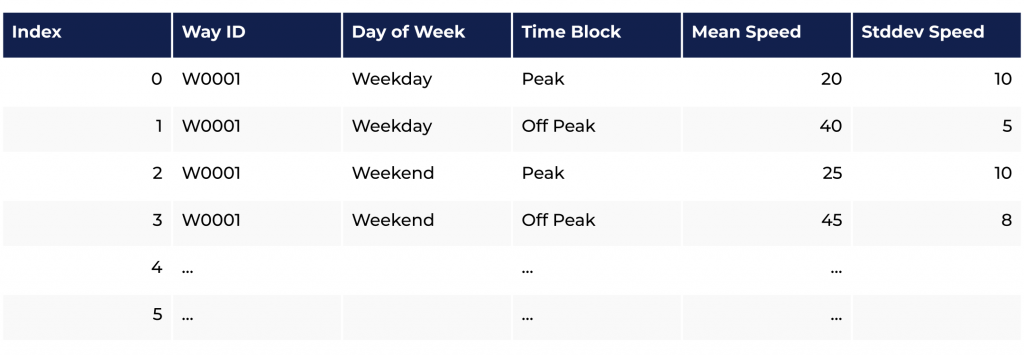
As traffic speeds vary throughout a day and differ from day to day, an alternative, more useful model for speed statistics is one that differentiates between weekdays and weekends, and among consecutive time blocks of a day. Figure 2 illustrates one such database table for storing traffic speed statistics. We refer to this design as a time-dependent speedmap.
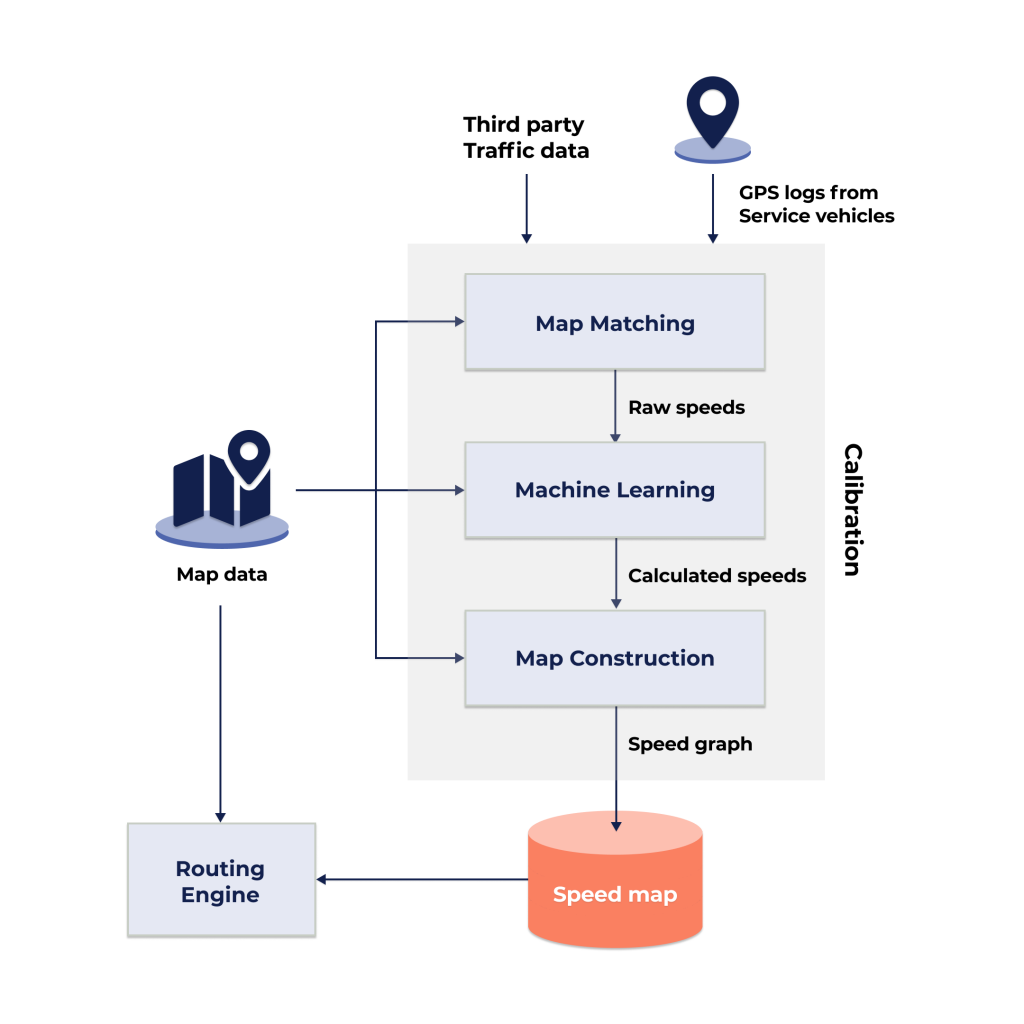
To populate the time-dependent speedmap, raw GPS logs of vehicles are processed in a multi-step speedmap calibration pipeline. As illustrated in Figure 3, speedmap calibration comprises a Map Matching step, a Machine Learning step, and finally, a Map Construction step.
The Map Matching step converts GPS logs of vehicles into raw speed data by matching noisy time-stamped vehicle positions to the road geometries of a trusted map source, such as OpenStreetMap (OSM). As OSM divides a road into connected segments called ‘ways’ and assigns a way ID to each segment, map-matched positions along the same way can be grouped to derive a raw speed for the way segment. The output from the Map Matching stage is a collection of raw speeds, each characterized by a way ID, a timestamp and a speed value.
At this point, a chicken-and-egg conundrum inevitably arises: a speedmap is required to start a service in a new area, but there isn’t in-house historical data available for calibration prior to the service. This is known as the ‘cold start’ issue. To address this, GPS data can be purchased from third party sources or gathered by putting a few GPS-logging vehicles on the road. For the services we operate, we adopt such a two-pronged approach in building up our initial repository of raw speed data for a new area. Over time, service operations would amass a significant volume of historical speed samples for each way, thereby enabling progressively more accurate statistical quantification in the next step of speedmap calibration.
The Machine Learning step encompasses three major processes: statistical aggregation, model training and prediction. In statistical aggregation, the raw speed samples are grouped by their way ID, weekday/weekend split and time block – collectively known as the grouping labels. Statistics like mean and standard deviation are then aggregated for each group. In model training, a machine learning model is trained to establish a relationship between the underlying map features of the ways, the grouping labels and the aggregated statistics. Based on our research, map features deemed useful for training include, but not limited to, the position, bearing, road class, number of lanes, width and maximum speed of the ways. Groups with insufficient number of speed samples or statistics classified as outliers would be excluded from the training. Finally, in the prediction process, the trained model is used to predict the statistics for all ways using their underlying map features and grouping labels as inputs to the trained model.
Map Construction is the final step of speedmap calibration pipeline, where the map data and the predicted speeds are analysed to generate additional speed-up information that allows the routing engine to accelerate its search for the fastest route through a set of waypoints. Two renown speed-up algorithms are Contraction Hierarchies and Multilevel Dijkstra. Contraction Hierarchies exploits the hierarchical nature of road networks to create direct links between important road nodes; Multilevel Dijkstra creates layers of varying road network sparsity that can be switched around during a search. Regardless of the speed-up algorithm used, the Map Construction step equips the routing engine with the essential data to carry out its path-finding tasks effectively.
Given a series of ordered waypoints, the routing engine searches for a string of connected ways that pass through the waypoints in the shortest time. The length of each way can be obtained from the map data, while the means and standard deviations of their speeds can be extracted from the calibrated speedmap. The overall mean and standard deviation journey time of the concatenated route can therefore be computed using established statistical theorems. With this information, the route can be scored and compared with another route candidate that serves another permutation of waypoints.
For lateness-sensitive services, such as employee transport that ferries employees from their homes to their workplaces, scheduling a route with mean journey time alone makes the service susceptible to variable traffic conditions, thus elevating the risk of lateness for work. With the aforementioned speedmap design, it is possible to alleviate the risk of lateness by estimating journey time pessimistically with the standard deviation data in the route scheduling process.
To ensure timeliness in capturing the shifts in traffic pattern brought about by long-term social-economic developments like population growth, urban planning, a shift in regulatory landscape and emergence of new transportation networks, speedmaps should be calibrated on a periodic cadence using speed data captured in a recent time window, spanning several months preceding the date of calibration.
As with most things modelled with historical data, a speedmap, notwithstanding its time-dependent intricacies, isn’t an infallible crystal ball. Cities typically bustle with ad hoc events – traffic accidents, a sudden rainstorm, a traffic light malfunction, a big truck hogging an entire highway, festive parades or the end of a pop concert – that can occur at various locations during service hours, creating and propagating congestion through chain reactions in dynamic, unpredictable and far-reaching ways. Such ad hoc events can, in reality, subvert a meticulously laid plan and result in service lateness.
While complete elimination of lateness is unattainable, occurrences of lateness can be strategically mitigated by factoring ad hoc incidents into the route planning process. Additional strategies can be put in place to complement the aforementioned pessimistic journey time approach. For example, extra service time buffers can be allocated to each stop to absorb the lateness incurred in preceding journeys, and drivers can be empowered to seek out alternative routes to help them circumvent visible congestion.
Author:

Chong Kok Seng
Data Scientist
SWAT Mobility
Chong Kok Seng holds a bachelor’s degree in Electrical and Computer Systems Engineering and a PhD in Robotics from Monash University. While serving as the principal engineer at Panasonic R&D Singapore, he authored and co-authored 30+ US and Japan patents. His current position is a data scientist leading the speedmap activities at SWAT Mobility.

Evgeny Makarov
Head of Data
SWAT Mobility
Evgeny Makarov holds a PhD degree in physics and mathematics from Nizhny Novgorod State University. Spent about 10 years at Institute of Applied Physics, later switched to industrial applications in public and commercial transportation and logistics. His current position is a Head of Data at swat mobility, leading the vehicle routing problem research and optimisation activities. Keeping several worlds’ best results on logistics optimisation with SWAT team.
Published in Telematics Wire