In these unprecedented times, COVID-19 has brought out a renewed and inspiring sense of collaboration in AI and research communities as Scale work toward solving pressing issues. But the pandemic has also exacerbated some of the difficulties of developing new technologies at Scale.
For example, as they shelter in place around the world, the promise of autonomous vehicles (AVs) to improve access to critical goods and services was never felt more relevant. But as they realize more ways these technologies could improve their lives, the essential data collection and testing that power them have rightly been suspended to ensure the safety of those involved.
That’s why Scale is launching PandaSet: a new open-source dataset for training machine learning (ML) models for autonomous driving released in partnership with the LiDAR manufacturer Hesai.
While many AV companies are turning to complementary techniques and simulated data to continue their work, there is often no substitute for high-quality data that captures the complex and often messy reality of driving in the real world.
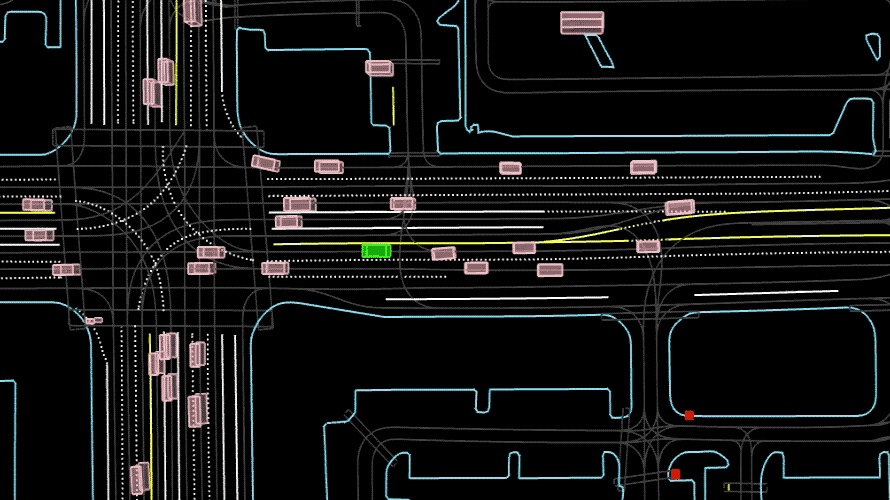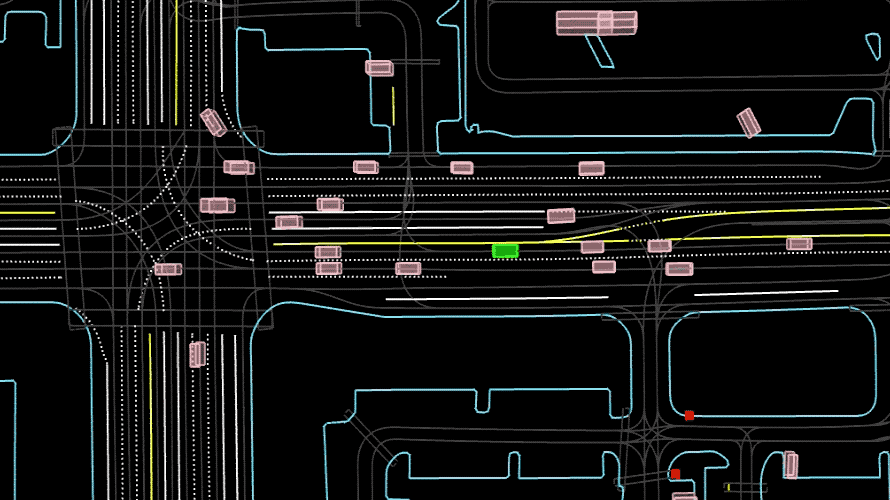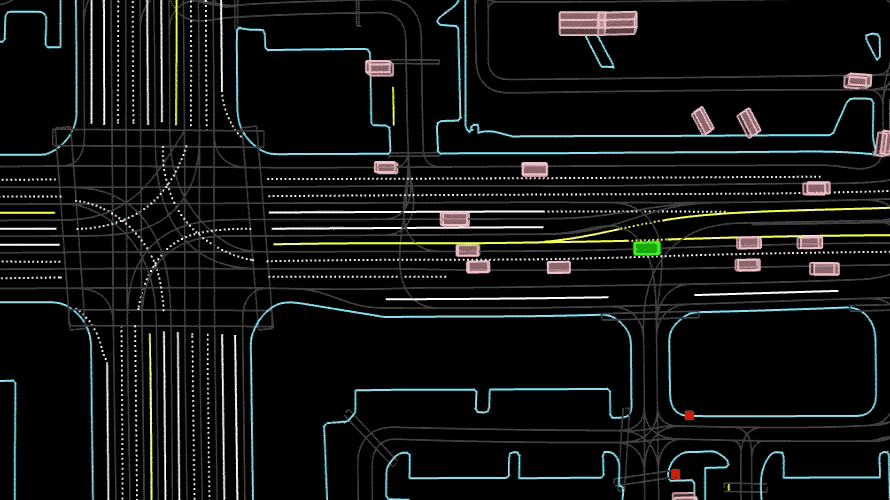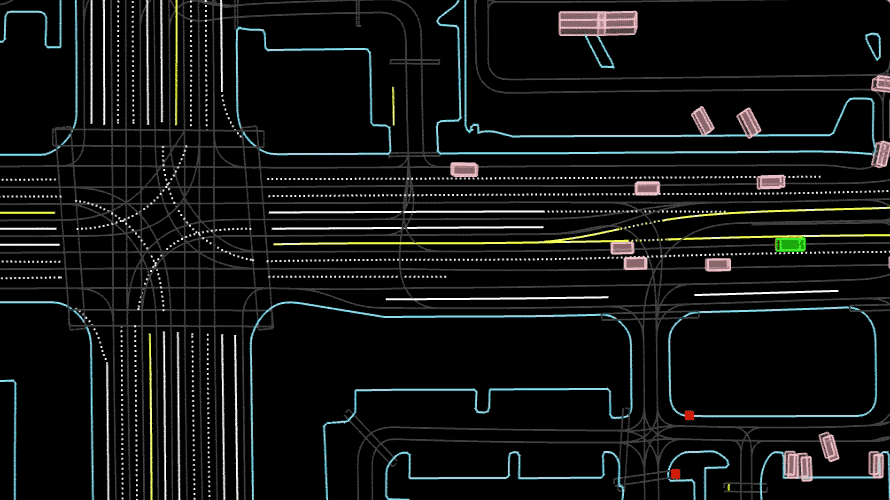
High-quality data is crucial to building safe and effective AV systems. PandaSet is the world’s first publicly available dataset to include both mechanical spinning and forward-facing LiDARs (Hesai’s Pandar64 and PandarGT)—allowing ML teams to take advantage of the latest technologies. It is also the first to be released without any major restrictions on its commercial use.
There are three reasons why they hope AV teams will find PandaSet to be a valuable resource: its content, its quality, and its no-cost commercial license.
Content
Covering some of the most challenging driving conditions for full level 5 autonomy, PandaSet includes complex urban environments, their dense traffic and pedestrians, steep hills, construction, and a variety of lighting conditions in the day, dusk and evening.
There are more than 48,000 camera images and over 16,000 LiDAR sweeps—more than 100 scenes of 8s each. Capturing sequences in busy urban areas also means there is a high density of useful information, with many more objects in each frame than in other datasets.
Quality
By combining the strengths of both mechanical spinning and forward-facing LiDARs, PandaSet captures the complex variables of urban driving in rich detail.
It also includes 28 different annotation classes for each scene as well as 37 semantic segmentation labels for the majority of scenes. With LiDAR data far beyond the capabilities of traditional cuboid labeling, it features Scale’s Point Cloud Segmentation that enables the highest precision and quality annotation of complex objects, such as smoke or rain.
PandaSet also features Scale’s market-leading Sensor Fusion technology, allowing ML teams to blend multiple LiDAR, RADAR and camera inputs into a single point cloud that allows for the semantic segmentation of different objects in LiDAR data. By allowing ML teams to exploit their LiDAR data much more systematically, this makes PandaSet ideal for building highly-performant autonomous systems.
No-cost commercial license
Many existing open-source datasets have restrictive licensing terms that allow only research or limited commercial uses. While that can be important for helping ensure data is used appropriately, they wanted to make PandaSet available to the entire community, democratizing access to the latest LiDAR technologies for ML teams around the world at a time when the barriers to data collection are higher.
They all want to accelerate the safe deployment of AVs—and the need for the right data has never been more pressing. By filling the gap for AI and ML developers who might otherwise be unable to build and test new technologies, they hope PandaSet will provide a useful resource for teams building a future for mobility that is safer and more accessible for everyone.